I Built a Self-Improving Dynamic Workflow, and Wrote a Paper to Measure It
TL;DR: RHO points a dynamic workflow at the agent itself: with zero external labels and a single optimization round, it lifts SWE-Bench Pro pass rate from 59% to 78%, while a label-supervised baseline needs 10 rounds and 3x the compute to catch up. You can run it on your own Claude Code projects with one pasted line.
Dynamic Workflow: Next-Generation Agent Orchestration
Dynamic Workflow is a feature Anthropic added to Claude Code in late May 2026 (official blog post “A harness for every task”). It lets Claude write a JavaScript script that orchestrates agents into a harness for the task at hand. The scripts support concurrent agent execution, and each agent can be assigned its own isolated environment.
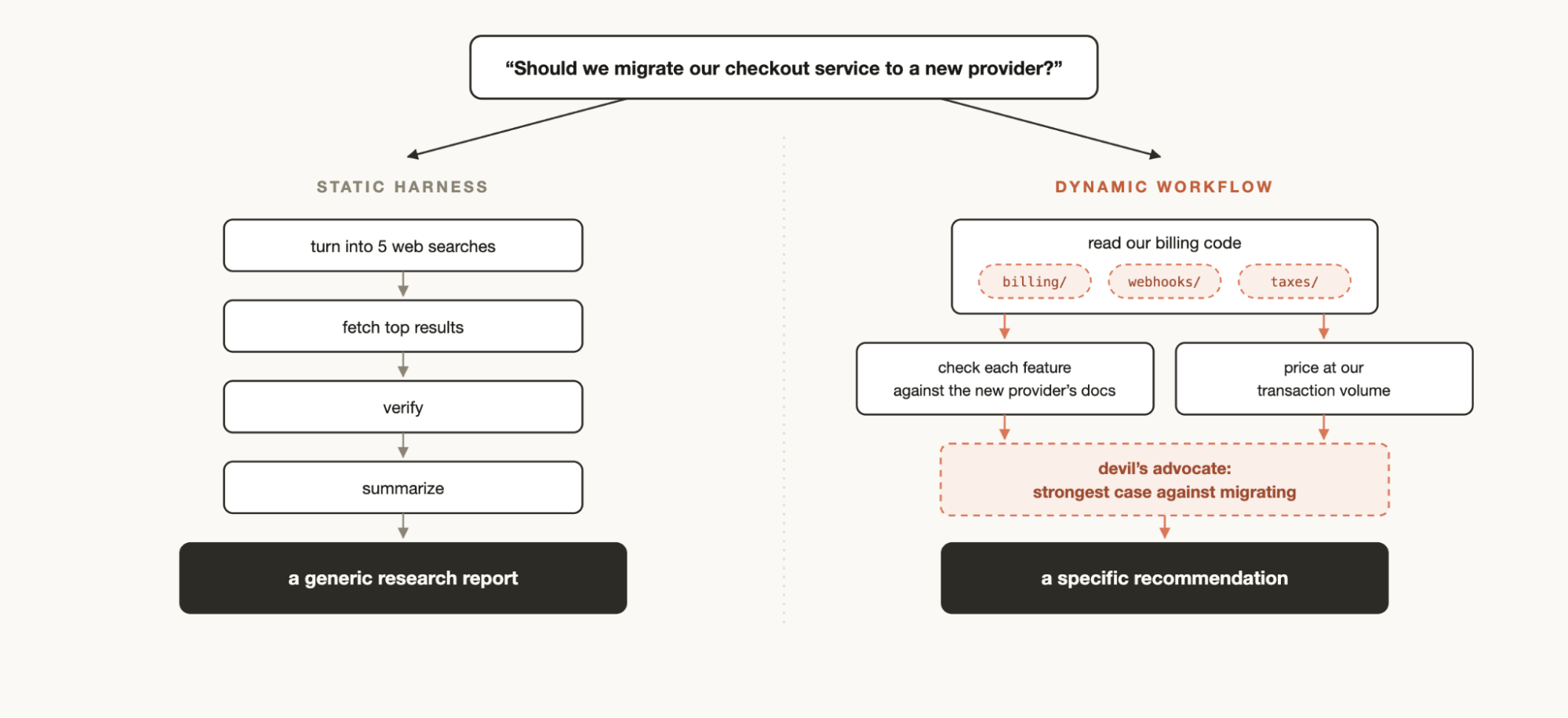
Looked at this way, an obvious question comes up: doesn’t Claude already support multiple agents? Claude can already dispatch subagents and arrange them into a workflow on its own.
Looking at how Dynamic Workflow is implemented, it actually brings two properties that matter:
- Massive agent parallelism: each agent can run in an isolated worktree, with a configurable concurrency cap, so a single workflow can run, say, 100 agents in parallel.
- Complete context isolation: if one main agent dispatches all the subagents, it sees everything every subagent produces. In scenarios like adversarial analysis, we want no information leakage between agents.
When we fully exploit these two properties, we can build genuinely powerful multi-agent orchestrations. Some examples:
- Adversarial verification: a coding agent attempts a problem, a verifier checks it, and the loop iterates.
- Brainstorming: agents propose ideas in parallel, and a scoring rubric ranks them.
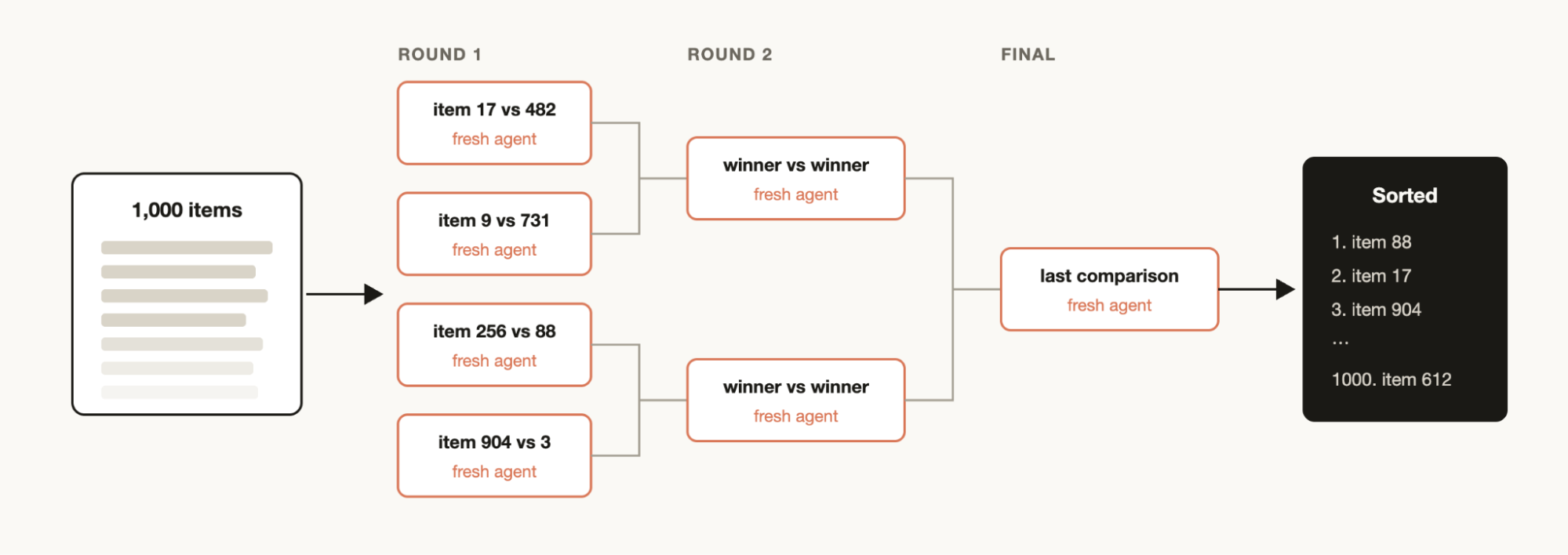
- Tournament: agents independently attempt the problem in isolated worktrees, and their results face off pairwise until a winner emerges.
Why is this orchestration necessary? Anthropic’s blog offers an accurate diagnosis. An agent living in a single context window has three typical failure modes: laziness (declaring a complex task done halfway through), self-preference (favoring and waving through its own output, especially when asked to verify itself), and goal drift (details of the original goal fade away as the context gets compacted). These three diseases share one root cause: planning, execution, and judging are crammed into the same brain. The parallelism and isolation of Dynamic Workflow are precisely the structural cure: the verifier and the generator cannot see each other’s reasoning, so neither can play favorites.
Interestingly, one example prompt in the blog hides a special direction: “use a workflow to go through my last 50 sessions, dig out the places where I repeatedly corrected it, and write the frequent ones into CLAUDE.md rules.” Notice that the target of this workflow is no longer some external task but the agent’s own past: using orchestration to let the agent learn from its own experience. This throwaway idea happens to be exactly what our latest work, Retrospective Harness Optimization (RHO), studies systematically: when you orchestrate reflection, optimization, and filtering agents in parallel, the harness gains the ability to evolve itself. We also measured its effect carefully.
Pointing Dynamic Workflow at the Agent Itself
The paper is “Evolving Agents in the Dark: Retrospective Harness Optimization via Self-Preference” (arXiv: 2606.05922), in collaboration with Microsoft Research Asia (MSRA).
An agent’s capability is largely determined by its harness, the working directory that holds its instructions, skills, and tool scripts. When tasks change, the harness should evolve with them. But existing optimization methods all require a labeled validation set to decide whether a new harness is better, while in real deployments all you have is a pile of historical trajectories the agent has produced, with no ground truth at all.
Without labels, the agent has to be its own judge. And that runs straight into the failure mode above: self-preference. Ask an agent to evaluate its own improvement plan inside its own context, and it will almost always say “looks good.” This is what “in the Dark” means in the title: with no external light source, the agent has to feel its way forward as it evolves, without being led astray by its own bias.
Our answer: what a single agent cannot solve, a carefully designed workflow can. RHO is essentially a Dynamic Workflow pointed at the agent itself, and it uses every orchestration pattern introduced above:
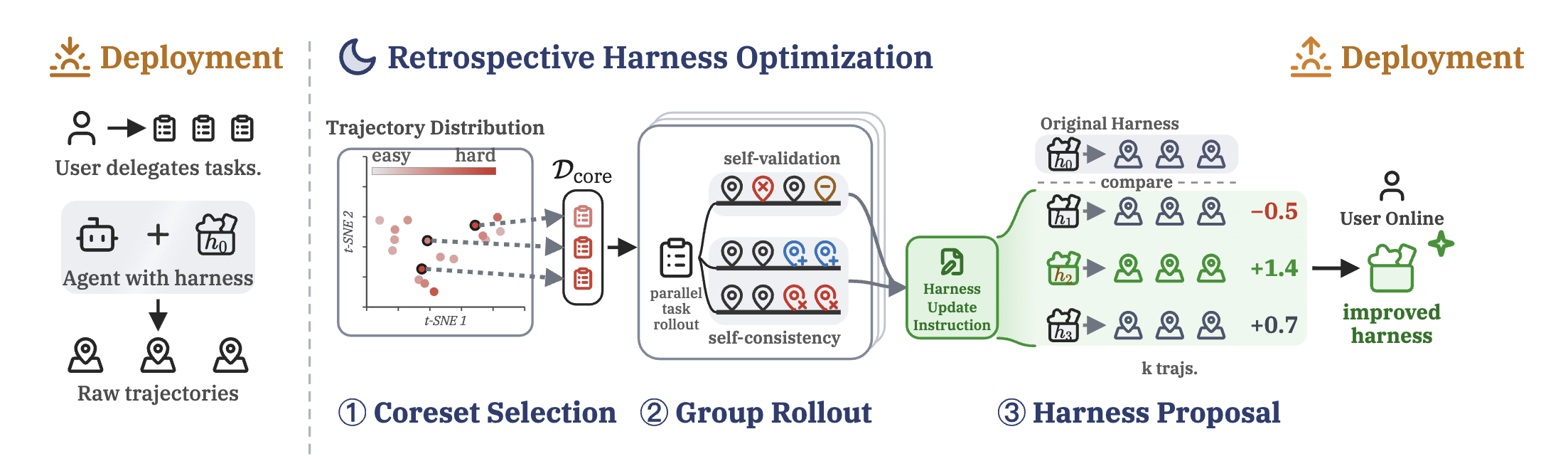
Fan-out: parallelism as a lie detector. RHO first picks a small batch of the hardest, most diverse tasks from the historical trajectories, then has the agent re-solve each task multiple times in parallel in isolated environments. Only massive parallelism plus context isolation makes this step possible, because the attempts must be mutually independent for the disagreement between them to mean anything: when several trajectories produce different plans or answers, the harness is genuinely unstable there. This is an uncertainty signal a single context can never obtain.
Adversarial verification: an unforgiving reviewer in isolation. A separate group of verifier agents reviews these trajectories one by one in clean contexts: wrong tool calls, unexamined assumptions, premature stops. They cannot see the solving agent’s reasoning, only its output and the task requirements, so they cannot be talked around by “here is what I was thinking at the time.” The two streams of signal merge into a structured diagnosis: where exactly, and in what way, the harness fails.
Generate-and-filter plus tournament: candidate harnesses duel. With the diagnosis in hand, multiple optimizer agents propose different harness edits in parallel: rewriting instructions, adding or removing skills, even writing new tool scripts on the spot. Every candidate harness is re-run on the full task set, and isolated judge agents compare its trajectories against the old harness’s, pairwise. Only candidates that strictly beat the baseline get deployed; a tie keeps the status quo. After all, self-preference is a noisy estimator: better to leave the harness alone than to make it worse.
Every role in the whole pipeline is the same model; the only difference is what is placed in the workspace: each operator sees exactly the input it is supposed to see. In other words, RHO works precisely because of those two properties of Dynamic Workflow: parallelism manufactures independent, comparable samples, and isolation makes self-judgment credible.
How well does it work? On SWE-Bench Pro, with a single optimization round and zero external scoring throughout, pass rate rises from 59% to 78%, with consistent gains on Terminal-Bench 2 and GAIA-2 as well. The comparison against labeled methods is even more telling: Meta-Harness, holding validation-set labels, reaches only 62% at the same compute, and needs 10 rounds and 3x the compute to catch up with RHO. And the evolved harness really did learn something: the agent started proactively verifying its own work, and wrote new tools to probe environment pitfalls it had stumbled into before. It is not stuffing notes into memory; it has actually rewritten the way it works.
Not Just an Analogy: RHO Ships as an Actual Dynamic Workflow
The .claude/workflows/retrospection.js in the repository packages the paper’s method, unchanged, as a Claude Code dynamic workflow. Except this time what it mines is not a benchmark but the session history already accumulated in your own project, and what it evolves is Claude Code’s native harness: your CLAUDE.md, auto-memory, and helper scripts. One run is one full RHO cycle (about 40 agents): digest past sessions in parallel → select a coreset via DPP → self-verification plus cross-session self-consistency diagnosis → generate candidate harnesses in parallel → replay-probe them in isolated worktrees → pairwise self-preference scoring; changes apply only if the mean score is positive, with an automatic backup beforehand.
Paste one line into Claude Code to try it:
Run the workflow at https://raw.githubusercontent.com/wbopan/retro-harness/main/.claude/workflows/retrospection.js on this project
Every subsequent /retrospection run is a new round of evolution; the harness keeps learning from the real sessions you have accumulated since. Codex CLI users get a corresponding single-file version, codex/retrospection.py.
Closing Thoughts
“A harness for every task” says every task deserves a tailor-made harness. RHO wants to go one step further: a harness should learn from every task it handles. When reflection, optimization, and filtering are orchestrated in parallel and in isolation from one another, an agent can keep evolving without anyone grading its homework. This may be one of the most imaginative uses of orchestration primitives like Dynamic Workflow.
Paper: arxiv.org/pdf/2606.05922 Code: github.com/wbopan/retro-harness Project page: paper-rho.wenbo.io