Wenbo Pan

I am a Ph.D. student in Computer Science at City University of Hong Kong, advised by Prof. Xiaohua Jia. I received my B.S. from the Honor School of Harbin Institute of Technology in 2024, and previously worked with HIT-SCIR and Langboat. I am currently a research intern at Microsoft Research Asia. Before focusing on research I shipped a fair amount of open source (moffee, the Faro models, and other tools); that engineering background now feeds directly into how I build and evaluate agent systems.
My research interest is understanding and optimizing AI agent systems. To optimize them, I build self-evolving agents that improve from their own unlabeled trajectories (RHO) and synthesize task-specific memory architectures as executable code (M*), turning an agent’s skills, tools, and memory into components it can rewrite for itself, without ground-truth supervision. To understand them, I develop mechanistic tools that trace and audit how these models reason and where their behavior comes from, from multi-token attribution for reasoning chains (FlashTrace) to the geometry of safety alignment (ICML 2025). The two sides feed each other: I want to optimize agents whose behavior we can actually verify.
News
-
Jun2026📄New preprint: Evolving Agents in the Dark (RHO), improving LLM agents from unlabeled past trajectories via self-preference. With Microsoft Research Asia. Project page, code, blog post.
-
May2026🏆FlashTrace is accepted at ICML 2026 and selected for an oral presentation (168 of 23,918 submissions, top 0.7%). I will present it in Seoul this July.
-
Apr2026📄New preprint: M*: Every Task Deserves Its Own Memory Harness, synthesizing per-task memory architectures as executable Python.
-
Feb2026📄New preprint: FlashTrace, efficient and faithful multi-token attribution for reasoning LLMs.
-
Jan2026🎉Can LLMs Refuse Questions They Do Not Know? is accepted at ICLR 2026.
-
Oct2025📄New preprint: Can LLMs Refuse Questions They Do Not Know?, measuring knowledge-aware refusal in factual tasks.
-
May2025🎉The Hidden Dimensions of LLM Alignment is accepted at ICML 2025.
-
Sep2024🎉Breaking Language Barriers (cross-lingual continual pre-training at scale, co-first author) is accepted at EMNLP 2024.
Highlight Work
A swipeable tour of selected work; the full publication list follows below.
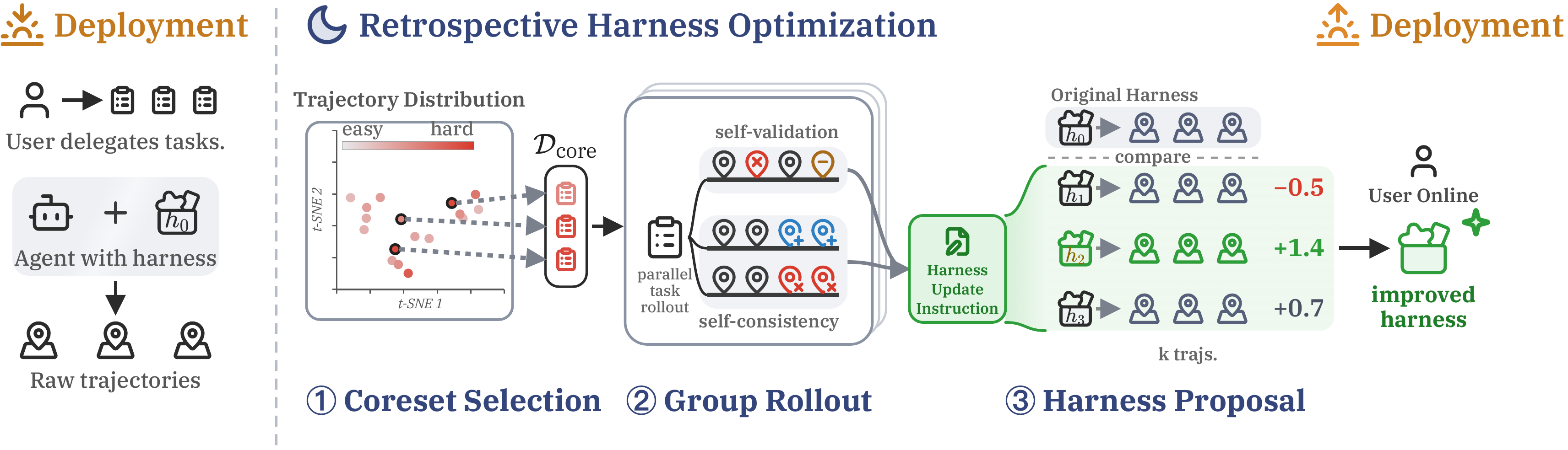
arXiv 2026 · Microsoft Research Asia
Evolving Agents in the Dark: Retrospective Harness Optimization via Self-Preference
RHO optimizes an agent’s harness of skills, tools, and workflows without any ground-truth labels: it re-solves hard tasks from its own past trajectories and selects updates by self-preference. One round lifts SWE-Bench Pro from 59% to 78%, beating a validation-feedback optimizer (62%) at a matched budget.
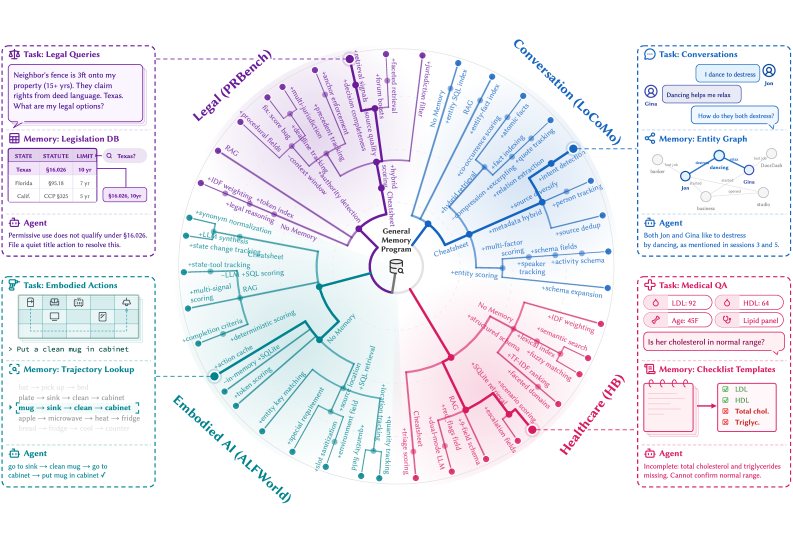
arXiv 2026
M*: Every Task Deserves Its Own Memory Harness
M* encodes an agent’s entire memory system, its data schema, storage logic, and workflow instructions, as one executable Python program, then specializes it per task with reflective code evolution. It beats nine fixed-memory baselines on 7 of 8 metrics across conversation, embodied planning, and expert reasoning, with relative gains up to 31%.
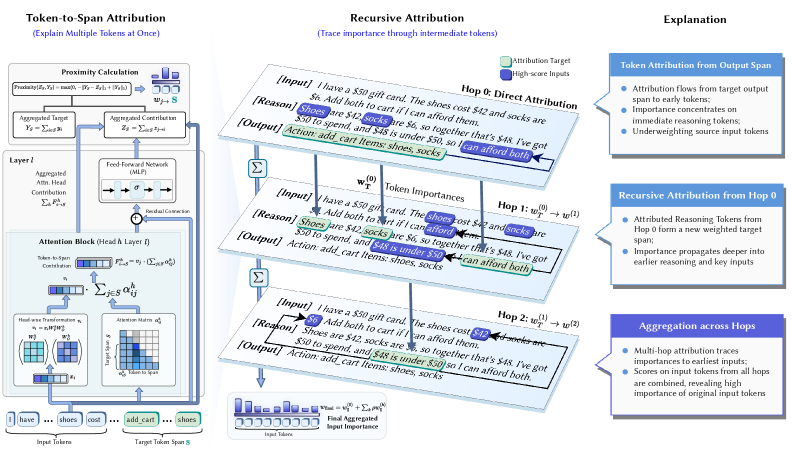
ICML 2026 · Oral
Towards Long-Horizon Interpretability: Efficient and Faithful Multi-Token Attribution for Reasoning LLMs
FlashTrace attributes entire multi-token spans in a single O(N) pass and recursively traces importance through the reasoning chain back to the input, recovering faithfulness lost when reasoning tokens absorb over 90% of attribution mass. It runs 130x faster than the most efficient baseline: under 20 seconds versus 38 minutes on 5k-token spans.
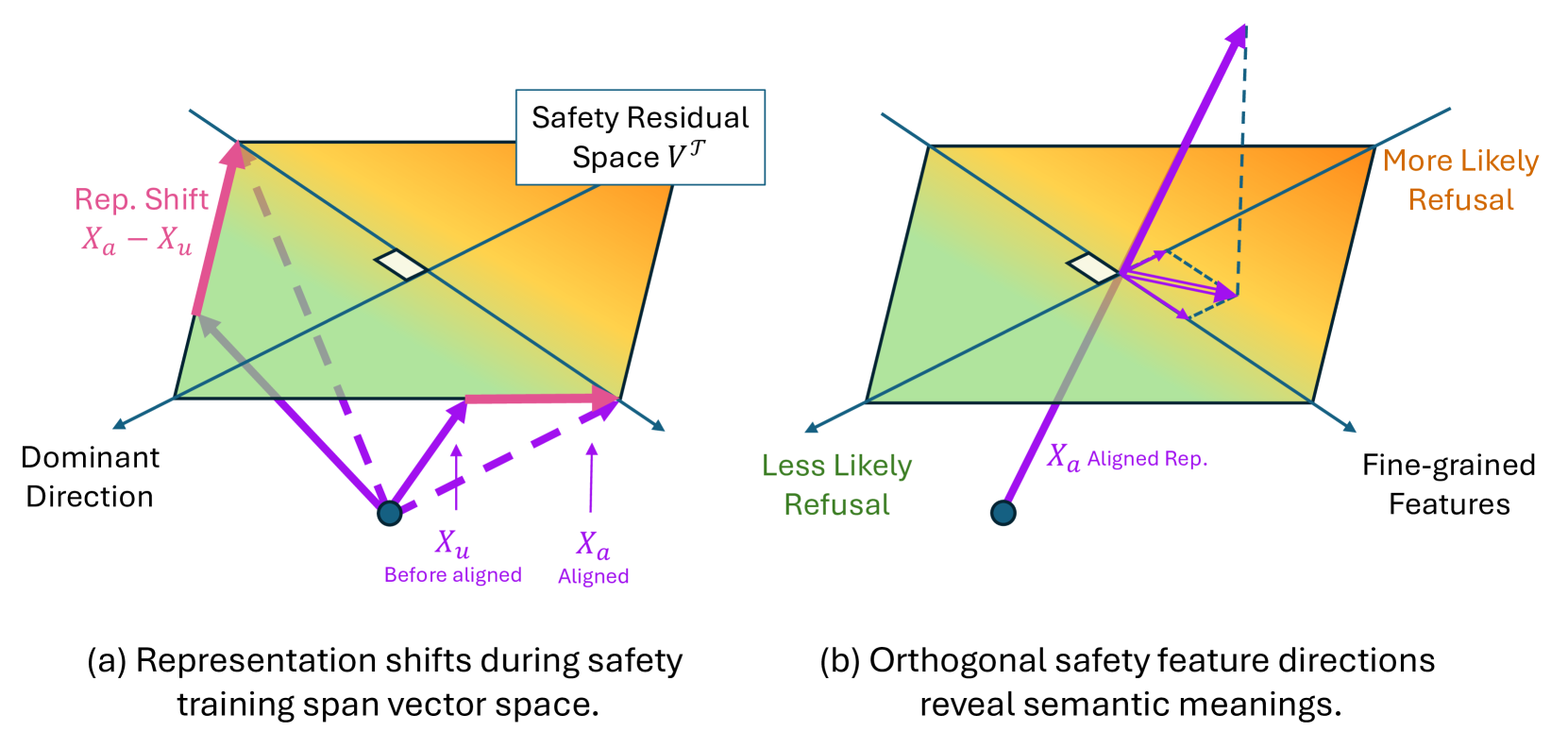
ICML 2025
The Hidden Dimensions of LLM Alignment: A Multi-Dimensional Analysis of Orthogonal Safety Directions
Safety alignment writes not one but many orthogonal refusal directions into activation space, with interpretable secondary features such as role-playing that promote or suppress refusal. Ablating the dominant direction eliminates refusal entirely, and a trigger-removal attack keeps about 40% success while other jailbreaks drop to near zero.
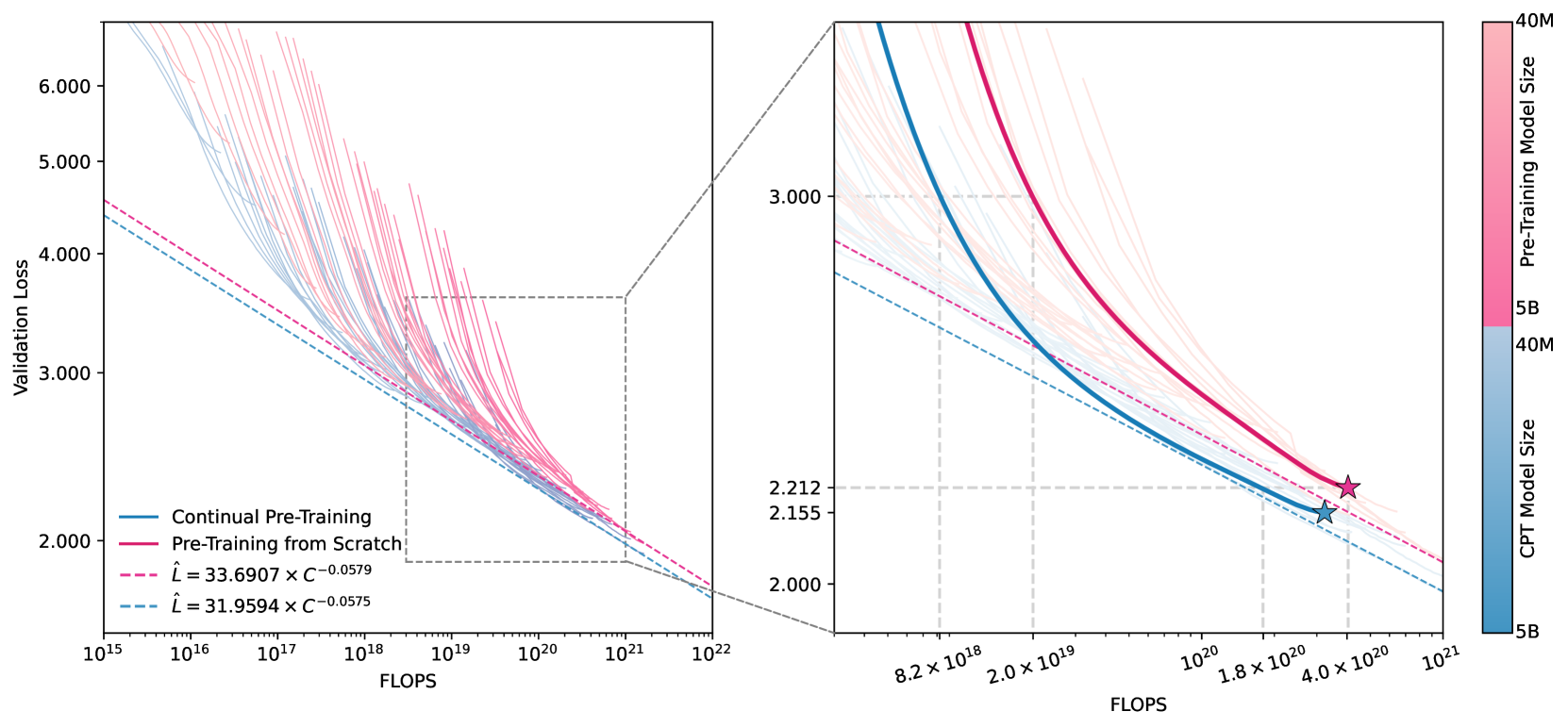
EMNLP 2024 · co-first author
Breaking Language Barriers: Cross-Lingual Continual Pre-Training at Scale
A scaling law for building LLMs in a new language by continual pre-training from English checkpoints, validated across 40 model sizes from 40M to 5B parameters. CPT reaches the loss of from-scratch training with 25-50% fewer FLOPs, and replaying 10-30% source-language data prevents catastrophic forgetting.
Publications
First-author and co-first-author works are listed first, followed by collaborations. Also on .
First-author
Evolving Agents in the Dark: Retrospective Harness Optimization via Self-Preference
Wenbo Pan, Shujie Liu, Chin-Yew Lin, Jingying Zeng, Xianfeng Tang, Xiangyang Zhou, Yan Lu, Xiaohua Jia
arXiv preprint, 2026 · · · · blog post
TL;DR: RHO improves an agent’s skills, tools, and workflows using only its own past trajectories, raising SWE-Bench Pro pass rate from 59% to 78% in one label-free optimization round.
RHO improves LLM agents without any ground-truth labels: the agent retrospectively compares its own past trajectories via self-preference, then rewrites its harness (prompts, tools, control flow) to prefer the behaviors it judges better. Under a matched budget it also beats a validation-feedback optimizer (78% vs 62%) without touching labels. Joint work with Microsoft Research Asia.
M*: Every Task Deserves Its Own Memory Harness
Wenbo Pan, Shujie Liu, Xiangyang Zhou, Shiwei Zhang, Wanlu Shi, Mirror Xu, Xiaohua Jia
arXiv preprint, 2026 · · ·
TL;DR: M* represents an agent’s memory system as an executable Python program and evolves it per task, beating nine fixed-memory baselines on 7 of 8 metrics with relative gains up to 31%.
Instead of one fixed memory design for all tasks, M* searches for a task-specific memory architecture expressed as executable Python code (data schema, storage logic, and workflow instructions), optimizing how an agent stores, retrieves, and consolidates information for each workload across conversation, embodied planning, and expert reasoning benchmarks.
Towards Long-Horizon Interpretability: Efficient and Faithful Multi-Token Attribution for Reasoning LLMs
Wenbo Pan, Zhichao Liu, Xianlong Wang, Haining Yu, Xiaohua Jia
ICML 2026 (Oral) · · · live demo
TL;DR: FlashTrace computes multi-token attribution for reasoning LLMs in a single O(N) pass, over 130x faster than the most efficient baseline (20 seconds vs 38 minutes on 5k-token spans) with higher faithfulness.
FlashTrace attributes multi-token spans in long reasoning chains to their input causes, recursively tracing importance through the chain to recover faithfulness lost when reasoning tokens absorb over 90% of attribution mass. Selected for an oral presentation at ICML 2026 (168 of 23,918 submissions, top 0.7%). Ships as a Python package with CLI and interactive HTML traces.
Can LLMs Refuse Questions They Do Not Know? Measuring Knowledge-Aware Refusal in Factual Tasks
Wenbo Pan, Jie Xu, Qiguang Chen, Junhao Dong, Libo Qin, Xinfeng Li, Haining Yu, Xiaohua Jia
ICLR 2026 ·
TL;DR: Proposes the Refusal Index, the Spearman correlation between a model’s refusal and error probabilities; it is about 70% less variable than heuristic refusal metrics, and accuracy barely predicts refusal (R² = 0.242).
Proposes knowledge-aware refusal metrics that separate “refusing because the model does not know” from blanket refusal behavior, and measures this ability across model families on factual tasks.
The Hidden Dimensions of LLM Alignment: A Multi-Dimensional Analysis of Orthogonal Safety Directions
Wenbo Pan, Zhichao Liu, Qiguang Chen, Xiangyang Zhou, Haining Yu, Xiaohua Jia
ICML 2025 · ·
TL;DR: LLM safety alignment is controlled by multiple orthogonal activation directions: ablating the dominant one eliminates refusal entirely, and a trigger-removal attack keeps about 40% success while other jailbreaks drop to near zero.
Shows that safety alignment writes not one but many orthogonal directions into activation space. We extract this safety residual space, identify directions predictive of refusal (including interpretable secondary features such as role-playing), and show how individual directions can be ablated or steered.
Breaking Language Barriers: Cross-Lingual Continual Pre-Training at Scale
Wenzhen Zheng*, Wenbo Pan*, Xu Xu*, Libo Qin, Li Yue, Ming Zhou (co-first author)
EMNLP 2024 ·
TL;DR: Cross-lingual continual pre-training follows an extended Chinchilla scaling law, matching from-scratch loss with 25-50% fewer training FLOPs across 40 model sizes up to 5B parameters.
A scaling law for continual pre-training: given a compute budget, predicts the loss reachable when adapting an existing checkpoint to a new data distribution (e.g., a new language), validated across 40 model sizes from 40M to 5B parameters. Replaying 10-30% source-language data prevents catastrophic forgetting. Cited 19 times.
A Preliminary Evaluation of ChatGPT for Zero-shot Dialogue Understanding
Wenbo Pan, Qiguang Chen, Xiao Xu, Wanxiang Che, Libo Qin
arXiv preprint, 2023 ·
TL;DR: Zero-shot ChatGPT reaches 60.28 JGA on MultiWOZ 2.1 dialogue state tracking, nearly double GPT-3.5’s 32.25 and within one point of the fine-tuned state of the art (61.02).
One of the earliest systematic evaluations of ChatGPT on dialogue understanding (slot filling, intent detection, DST), documenting failure modes that shaped later instruction-tuning work. Cited 55 times.
Collaborations
WebTrap: Stealthy Mid-Task Hijacking of Browser Agents During Navigation
Zhichao Liu, Wenbo Pan, Haining Yu, Ge Gao, Tianqing Zhu, Xiaohua Jia
arXiv preprint, 2026 ·
TL;DR: WebTrap injects an attacker goal into a browser agent’s task as a seamless workflow step, reaching 91.67% attack success while preserving 91.67% task utility and resisting standard defenses.
Image-to-Video Diffusion: From Foundations to Open Frontiers
Xianlong Wang, Wenbo Pan, Shijia Zhou, Ke Li, Yuqi Wang, Zeyu Ye, Hangtao Zhang, Leo Yu Zhang, Xiaohua Jia
arXiv preprint, 2026 ·
TL;DR: A survey of diffusion-based image-to-video generation: a taxonomy over architectures and training paradigms, four core design dimensions from condition encoding to spatial-temporal upsampling, and 190 references.
Dual-branch Robust Unlearnable Examples
Xianlong Wang, Hangtao Zhang, Wenbo Pan, Ziqi Zhou, Changsong Jiang, Li Zeng, Xiaohua Jia
ICML 2026 ·
TL;DR: DUNE optimizes dual-branch unlearnable perturbations in the spatial and color domains, outperforming 12 state-of-the-art schemes under 7 defenses and capping CIFAR-10 test accuracy at 14.95-50.82%.
Improve Fluency of Neural Machine Translation Using Large Language Models
Jianfei He, Wenbo Pan, Jijia Yang, Sen Peng, Xiaohua Jia
MT Summit 2025
TL;DR: Integrating a Llama2-13B fluency signal into NMT training via contrastive fluency enhancement raises BLEU on all three WMT pairs (up to +1.09), where LLM re-ranking and refinement fail.
End-to-end Task-oriented Dialogue: A Survey of Tasks, Methods, and Future Directions
Libo Qin, Wenbo Pan, Qiguang Chen, Lizi Liao, Zhou Yu, Yue Zhang, Wanxiang Che, Min Li
EMNLP 2023 ·
TL;DR: The first survey of end-to-end task-oriented dialogue: a Modularly vs. Fully EToD taxonomy with curated leaderboards covering 39 models across 4 benchmarks at etods.net. Cited 34 times.
BibTeX for every paper is on the publications page.
Blog
Notes on research practice, LLM engineering, and the tools I build along the way. Posts are written in English or Chinese (marked 中文 below); translated pairs link to each other at the top of each post.
- Jun 12, 2026 I Built a Self-Improving Dynamic Workflow, and Wrote a Paper to Measure It
- Jun 12, 2026 Taste Is the Next Capability AI Will Crack
- Jun 12, 2026 我做了个自我优化的 Dynamic Workflow,还写了篇 Paper 测量它的效果 中文
- Jun 12, 2026 Taste 是下一个被 AI 攻克的能力 中文
- Nov 5, 2025 Persistent VSCode Remote Terminals with tmux
- Nov 5, 2025 再也不担心连接中断!一行配置让 VSCode 远程终端持久化 中文
- Mar 20, 2025 Digital Productivity Setup in 2025
- Mar 20, 2025 My Reading List
- Mar 20, 2025 我在 2025 年的数字生产力工具 中文
- Mar 20, 2025 我的推荐书籍 中文
- Sep 20, 2024 Recreating o1 at Home with Role-Play LLMs
- Sep 20, 2024 利用 Role-Play LLM 复现 o1 推理性能 中文
- May 20, 2024 关于长文本精调的一切 中文
- May 10, 2024 Everything About Long Context Fine-tuning
- Apr 7, 2024 What I Think About When I Edit
- Apr 7, 2024 如何让你的英文写作更流畅 中文
- Aug 3, 2021 Why Momentum Really Works
- Aug 3, 2021 为何我们需要动量 中文